It may be that today’s large neural networks are slightly conscious. — Ilya Sutskever
Introduction
Week 3 of my GSoC’25 journey was all about scaling up: from setup and debugging to running experiments with LLMs on Hindi information extraction. This week, I evaluated the performance of current open source LLMs on Open Information Extraction (OIE) tasks. We established a framework to test the performance of a LLM through ollama on a full Hindi-BenchIE dataset. We then systematically compared models and prompting strategies, and tried to figure out what works (and what doesn’t) for extracting structured knowledge from Hindi text.
This post explains our setup, methodology, and results.
Framework Overview
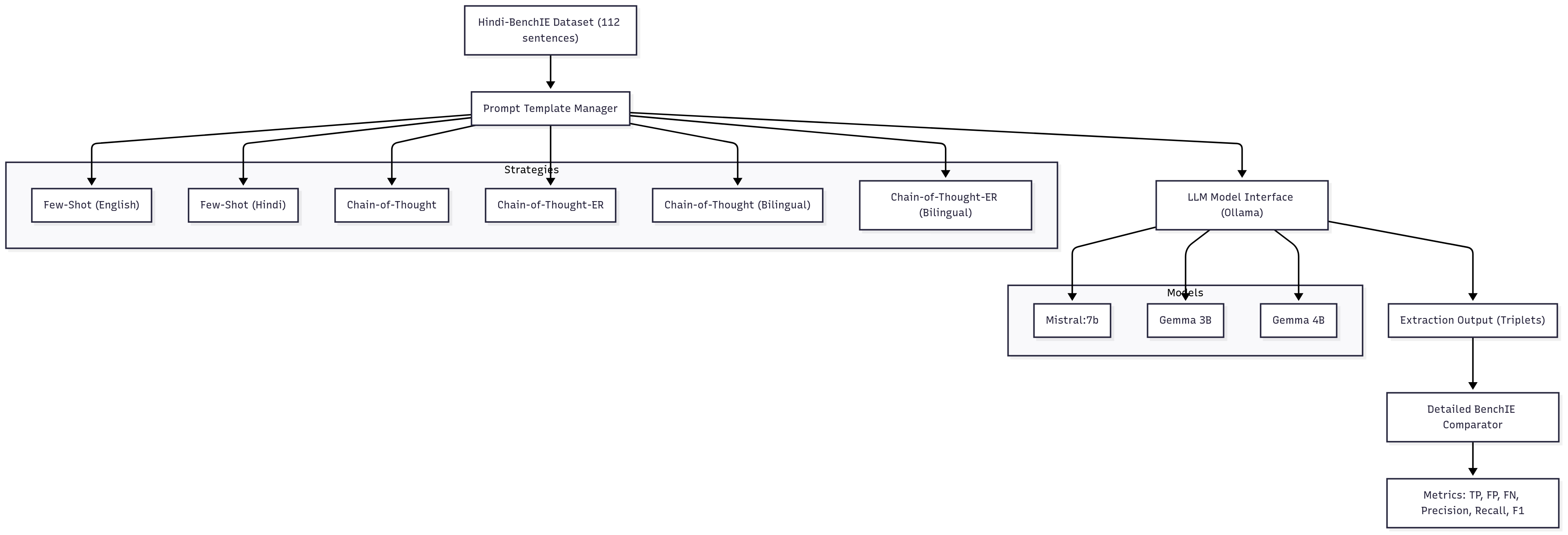
Our framework is simple. We have 3 main components:
- Prompt Template Manager - Responsible for returning the prompt based on the prompt strategy and params
- LLM Model Interface - Interface for interacting with the llm using the ollama API
- BenchIE Evaluator - Evaluates the performance of the extractions using the Hindi BenchIE logic.
The Dataset: Hindi-BenchIE
The evaluation is done on the Hindi-BenchIE dataset—a gold-standard collection of 112 Hindi sentences, each annotated with clusters(possibilities) of subject-predicate-object (SPO) triples. This dataset is challenging: sentences are diverse, often ambiguous, and require nuanced understanding to extract the correct relations.
Each sentence comes with multiple valid clusters of extractions, reflecting the inherent ambiguity and richness of the language. Our goal: see how close LLMs can get to human-level extraction on this benchmark.
Models and Prompting Strategies
We evaluated three LLMs:
- Mistral 7B
- Gemma 3B
- Gemma 4B
For each model, we tested a suite of prompting strategies:
- Few-Shot (English): Classic prompt with a handful of English examples.
- Few-Shot (Hindi): Same, but in Hindi.
- Chain-of-Thought: Prompting the model to “think step by step” before extracting triples.
- Chain-of-Thought-ER: Chain-of-thought with explicit evidence reasoning (ER) steps.
- Bilingual Variants: Mixing English and Hindi in prompts (english instructions + hindi examples), to test if code-switching helps.
This matrix of models × strategies lets us probe not just which LLM is best, but how to talk to it for optimal extraction.
Evaluation: How We Measure Extraction Quality
Extracting triples is only half the battle. To measure how well our models perform, we compare their outputs to the gold standard using three core metrics:
- True Positives (TP): Model extractions that match a gold-standard triple.
- False Positives (FP): Model extractions that don’t match any gold triple (hallucinations).
- False Negatives (FN): Gold triples the model missed entirely.
From these, we compute:
-
Precision: What fraction of the model’s extractions are actually correct?
Precision = TP/(TP + FP) -
Recall: What fraction of the gold triples did the model find?
Recall = TP/(TP + FN) -
F1 Score: The harmonic mean of precision and recall—a single number that balances both.
F1 = 2*(Precision * Recall) / (Precision + Recall)
Intuition:
- High precision, low recall: Model is cautious, but misses a lot.
- High recall, low precision: Model finds most gold triples, but makes many mistakes.
- High F1: The sweet spot—lots of correct extractions, few errors.
Our evaluation script does a detailed, cluster-aware comparison for each sentence, ensuring that partial matches and alternative valid extractions are handled fairly.
Results: What Did We Learn?
We ran 18 experiments (3 models × 6 strategies), generating thousands of extractions. Here are the highlights:
- Best Model/Strategy:
- Gemma 4B + Chain-of-Thought-ER with english instructions and hindi examples achieved the highest F1 score: 0.25 (Precision: 0.27, Recall: 0.24).
Key Insights:
- Bigger is better: Gemma 4B consistently outperformed smaller models.
- Evidence-based prompting wins: Chain-of-Thought-ER strategies (with explicit reasoning) outperformed vanilla chain-of-thought and few-shot prompts.
- ICL matters In context learning examples matter. By improving and increasing the examples to better represent the complexity of hindi text in the prompt, we can extract better performance.
- Bilingual prompts Models, gemma especially, performs slightly better with english instructions + hindi examples.
- Absolute numbers are low: Even the best F1 is ~0.25. Hindi extraction is hard—there’s plenty of room for improvement.
You can find the detailed code and results here: code, results.
Reflections and Next Steps
This week was a crash course in the realities of LLM-based information extraction for low-resource languages. The models are powerful, but far from perfect and prompting matters—a lot.
Next up:
- Prune underperforming strategies and focus on what works.
- Add new models (Llama 3.2, more Gemma variants).
- Try the ReAct framework of prompting using function-calling and more. Keep pushing the F1 ceiling higher.
- Read up on link prediction.
Stay tuned for more experiments and more insights as I try to push the boundaries of LLM assisted OIE on hindi text.